About Me

|
I am Hang Zhang (张航), currently Head of the VLA Foundation Model Team at XPeng, where I lead the development of next-generation autonomous driving systems using Vision-Language-Action (VLA) foundation models for L3 and L4 production vehicles.
Previously, I was a Senior Staff Applied Research Scientist at Cruise, leading efforts in detection, segmentation, and perception model consolidation.
Before Cruise, I was a Research Scientist at Meta, where I led the development of a scalable neural architecture optimization platform that supports AI models on Instagram, Portal, and VR headsets for tasks such as person understanding, AR / VR rendering, and ads ranking.
Earlier in my career, I was a Senior Applied Scientist at Amazon AI, working on deep learning, computer vision, and the MXNet framework. During that time, we developed the ResNeSt model, which achieved state-of-the-art results on multiple vision benchmarks.
Beyond my work, I am also enthusiastic in contributing to open source projects, including
[D2Go Toolkit,
PyTorch Encoding Toolkit,
AutoGluon Toolkit,
GluonCV Toolkit,
Apache MXNet].My research has been cited more than 10,000 times in Google Scholar, and my open-source contributions have received more than 10,000 stars on GitHub.
|
- New! [Dec, 2025] We're hiring Research Scentist Interns on VLA models, Feel free to reach out to me directly.
- New! [Feb, 2025] We are building E2E VLM foundation models for the next generation of autonomous driving. Jobs are opening a at all levels. Feel free to reach out to me directly.
- New! [Apr, 2024] We're hiring research interns on multi-modal long range 3D object detection for 2024, feel free to reach out to me direclty.
- New! [Oct, 2022] We're hiring research interns on 3D detection for 2023, feel free to reach out to me direclty.
- New! [Sep, 2022] I have spent a wonderful time at Meta and am starting my new journey at Cruise. Thanks my colleagues at Meta for the great collaboration and help!
- New! [Oct, 2021] We're hiring research interns for 2022, feel free to reach out to me direclty.
- New! [Mar, 2021] Check out the D2Go toolkit from our team [blog, github].
- New! [Sep, 2020] Our paper Differential Viewpoints for Ground Terrain Material Recognition is accepted to PAMI .
- New! [Jun, 2020] Welcome to attend our online CVPR2020 Tutorial on "From HPO to NAS: Automated Deep Learning".
- New! [May, 2020] I have open sourced the re-implementations for RegNet search and Fast AutoAugment.
- New! [Apr, 2020] We have released ResNeSt models and training code on GitHub..
- New! [Jun, 2019] AutoGluon is out, checkout the automatic deep learning toolkit at autogluon.mxnet.io .
- New! [Jun, 2019] I will co-organize the "Everything You Need to Know to Reproduce SOTA Deep Learning Models" tutorial at ICCV 2019 .
- New! [Feb, 2019] Two papers are accepted to CVPR 2019 .
- New! [Jun, 2018] We have released the source code of EncNet with pretrained models.
- New! [Mar, 2018] We have released Synchronized Cross-GPU Batch Normalization using MXNet Gluon and PyTorch.
- New! [Feb, 2018] Two papers are accepted to CVPR 2018 (1 oral + 1 poster).
- New! [Sep, 2017] I have defended my PhD thesis and will be working with Amazon AI.
- New! [Apr, 2017] We have released PyTorch version of [MSG-Net & Neural Style baseline] and [Deep Encoding].
- New! [Apr, 2017] I am selected to attend the CVPR 2017 Doctoral Consortium in Hawaii.
- New! [Mar, 2017] We have released the demo video and the code for MSG-Net.
- New! [Feb, 2017] Two papers are accepted to CVPR 2017.
- New! [Dec, 2016] We have released the code for Deep Encoding.
|
paper
abstract
bibtex
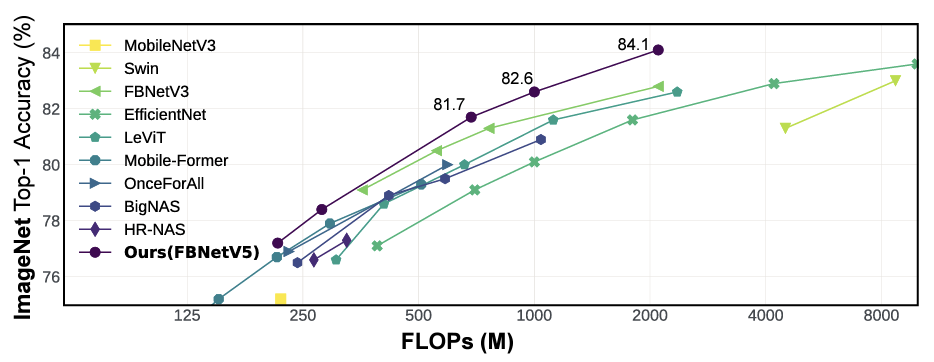
Neural Architecture Search (NAS) has been widely adopted to design accurate and efficient image classification models. However, applying NAS to a new computer vision task still requires a huge amount of effort. This is because 1) previous NAS research has been over-prioritized on image classification while largely ignoring other tasks; 2) many NAS works focus on optimizing task-specific components that cannot be favorably transferred to other tasks; and 3) existing NAS methods are typically designed to be "proxyless" and require significant effort to be integrated with each new task's training pipelines. To tackle these challenges, we propose FBNetV5, a NAS framework that can search for neural architectures for a variety of vision tasks with much reduced computational cost and human effort. Specifically, we design 1) a search space that is simple yet inclusive and transferable; 2) a multitask search process that is disentangled with target tasks' training pipeline; and 3) an algorithm to simultaneously search for architectures for multiple tasks with a computational cost agnostic to the number of tasks. We evaluate the proposed FBNetV5 targeting three fundamental vision tasks -- image classification, object detection, and semantic segmentation. Models searched by FBNetV5 in a single run of search have outperformed the previous stateof-the-art in all the three tasks: image classification (e.g., +1.3% ImageNet top-1 accuracy under the same FLOPs as compared to FBNetV3), semantic segmentation (e.g., +1.8% higher ADE20K val. mIoU than SegFormer with 3.6x fewer FLOPs), and object detection (e.g., +1.1% COCO val. mAP with 1.2x fewer FLOPs as compared to YOLOX). |
|
paper
abstract
bibtex
slides
code
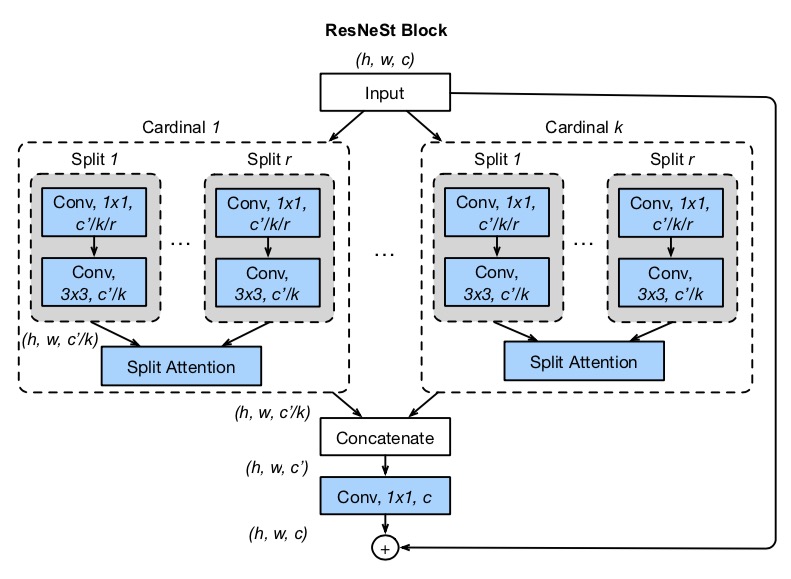
While image classification models have recently continued to advance, most downstream applications such as object detection and semantic segmentation still employ ResNet variants as the backbone network due to their simple and modular structure. We present a simple and modular Split-Attention block that enables attention across feature-map groups. By stacking these Split-Attention blocks ResNet-style, we obtain a new ResNet variant which we call ResNeSt. Our network preserves the overall ResNet structure to be used in downstream tasks straightforwardly without introducing additional computational costs. ResNeSt models outperform other networks with similar model complexities. For example, ResNeSt-50 achieves 81.13% top-1 accuracy on ImageNet using a single crop-size of 224 × 224, outperforming previous best ResNet variant by more than 1% accuracy. This improvement also helps downstream tasks including object detection, instance segmentation and semantic segmentation. For example, by simply replace the ResNet-50 backbone with ResNeSt-50, we improve the mAP of Faster-RCNN on MS-COCO from 39.2% to 42.3% and the mIoU for DeeplabV3 on ADE20K from 42.1% to 45.1%. |

|
paper
abstract
bibtex
Recent work has achieved great success in utilizing global contextual information for semantic segmentation, including increasing the receptive field and aggregating pyramid feature representations. In this paper, we go beyond global context and explore the fine-grained representation using co-occurrent features by introducing Co-occurrent Feature Model, which predicts the distribution of co-occurrent features for a given target. To leverage the semantic context in the co-occurrent features, we build an Aggregated Co-occurrent Feature (ACF) Module by aggregating the probability of the co-occurrent feature within the co-occurrent context. ACF Module learns a fine-grained spatial invariant representation to capture co-occurrent context information across the scene. Our approach significantly improves the segmentation results using FCN and achieves superior performance 54.0% mIoU on Pascal Context, 87.2% mIoU on Pascal VOC 2012 and 44.89% mIoU on ADE20K datasets with ResNet-101 base network. |
|
paper
abstract
bibtex
code
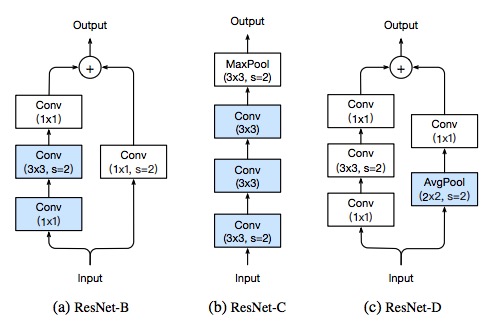
Much of the recent progress made in image classification research can be credited to training procedure refinements, such as changes in data augmentations and optimization methods. In the literature, however, most refinements are either briefly mentioned as implementation details or only visible in source code. In this paper, we will examine a collection of such refinements and empirically evaluate their impact on the final model accuracy through ablation study. We will show that, by combining these refinements together, we are able to improve various CNN models significantly. For example, we raise ResNet-50’s top-1 validation accuracy from 75.3% to 79.29% on ImageNet. We will also demonstrate that improvement on image classification accuracy leads to better transfer learning performance in other application domains such as object detection and semantic segmentation. |
|
paper
abstract
bibtex
code
talk
slides
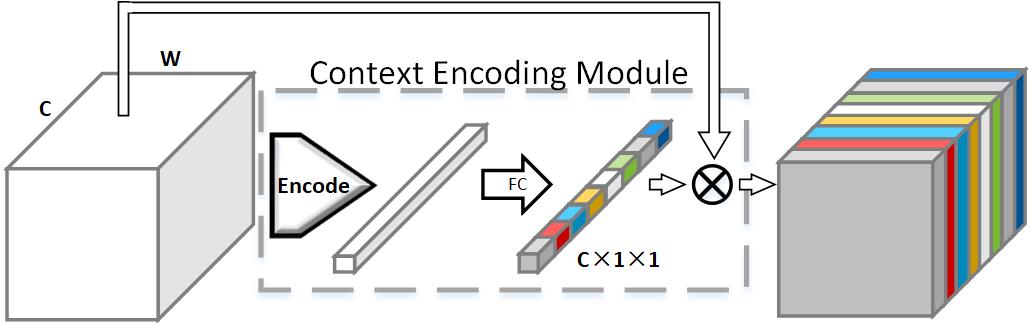
Recent work has made significant progress in improving spatial resolution for pixelwise labeling with Fully Convolutional Network (FCN) framework by employing Dilated/Atrous convolution, utilizing multi-scale features and refining boundaries. In this paper, we explore the impact of global contextual information in semantic segmentation by introducing the Context Encoding Module, which captures the semantic context of scenes and selectively highlights class-dependent featuremaps. The proposed Context Encoding Module significantly improves semantic segmentation results with only marginal extra computation cost over FCN. Our approach has achieved new state-of-the-art results 51.7% mIoU on PASCAL-Context, 85.9% mIoU on PASCAL VOC 2012. Our single model achieves a final score of 0.5567 on ADE20K test set, which surpasses the winning entry of COCO-Place Challenge 2017. In addition, we also explore how the Context Encoding Module can improve the feature representation of relatively shallow networks for the image classification on CIFAR-10 dataset. Our 14 layer network has achieved an error rate of 3.45%, which is comparable with state-of-the-art approaches with over 10 times more layers. |
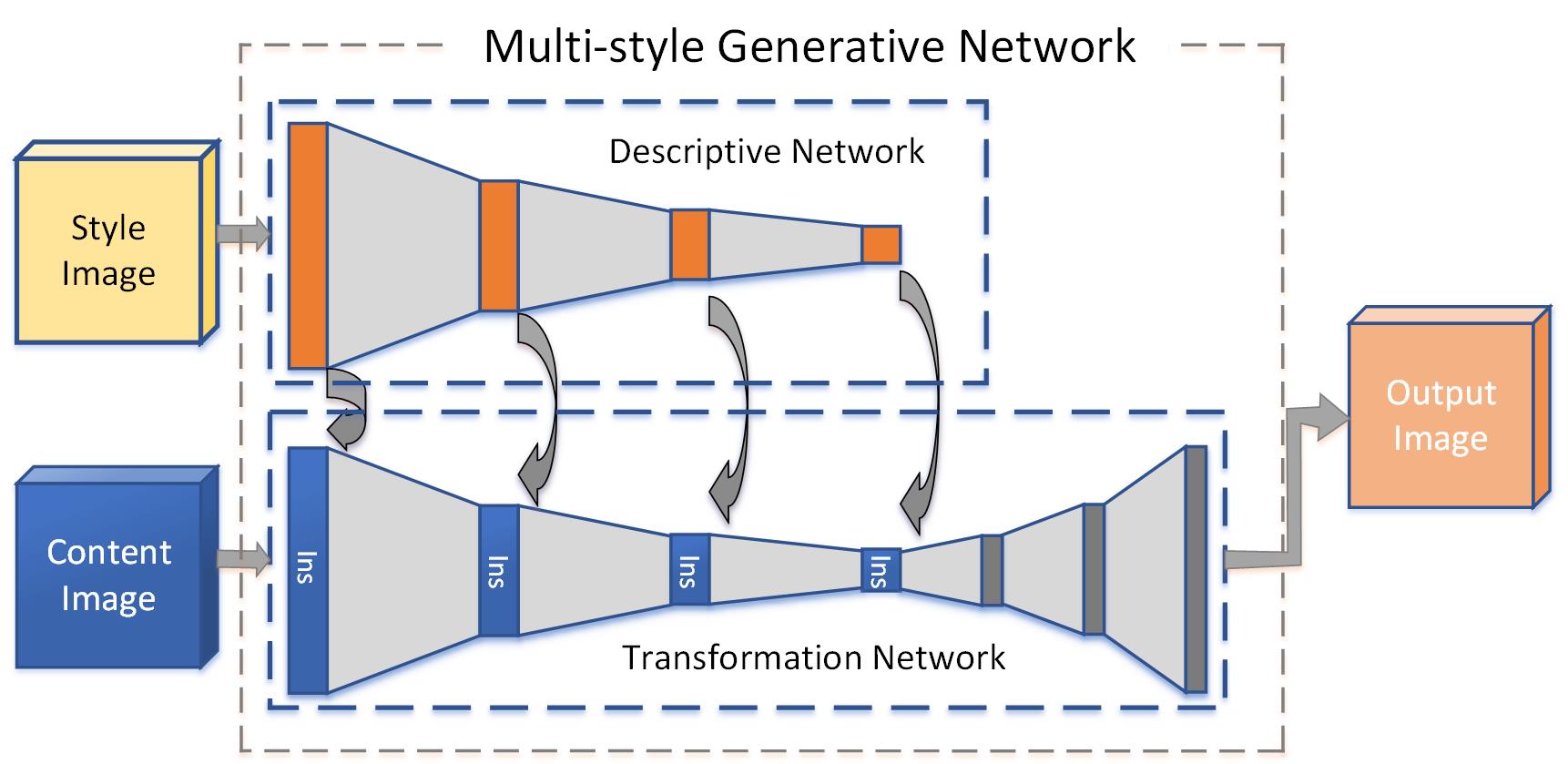
|
paper
abstract
bibtex
code
video
project
poster
Recent work in style transfer learns a feed-forward generative network to approximate the prior optimization-based approaches, resulting in real-time performance. However, these methods require training separate networks for different target styles which greatly limits the scalability. We introduce a Multi-style Generative Network (MSG-Net) with a novel Inspiration Layer, which retains the functionality of optimization-based approaches and has the fast speed of feed-forward networks. The proposed Inspiration Layer explicitly matches the feature statistics with the target styles at run time, which dramatically improves versatility of existing generative network, so that multiple styles can be realized within one network. The proposed MSG-Net matches image styles at multiple scales and puts the computational burden into the training. The learned generator is a compact feed-forward network that runs in real-time after training. Comparing to previous work, the proposed network can achieve fast style transfer with at least comparable quality using a single network. The experimental results have covered (but are not limited to) simultaneous training of twenty different styles in a single network. The complete software system and pre-trained models will be publicly available upon publication. |

|
paper
abstract
bibtex
code
blog
poster
slides
We propose a Deep Texture Encoding Network (TEN) with a novel Encoding Layer integrated on top of convolutional layers, which ports the entire dictionary learning and encoding pipeline into a single model. Current methods build from distinct components, using standard encoders with separate off-the-shelf features such as such as SIFT descriptors or pre-trained CNN features for material recognition. Our new approach provides an end-to-end learning framework, where the inherent visual vocabularies are learned directly from the loss function. That is, the features, dictionaries and the encoding representation for the classifier are all learned simultaneously. The representation is orderless and therefore is particularly useful for material and texture recognition. This Encoding Layer generalizes robust residual encoders such as VLAD and Fisher Vectors, and has the property of discarding domain specific information which makes the learned convolutional features easier to transfer. Additionally, joint training using multiple datasets of varied sizes and class labels is supported resulting in increased recognition performance. The experimental results show superior performance as compared to state-of-the-art methods using gold-standard databases such as MINC-2500, Flicker Material Database, KTH-TIPS-2b, and a new ground terrain multiview database. The source code for the complete system are publicly available. |