Deep Encoding
 |
This is a CVPR 2017 submission Deep TEN: Texture Encoding Network. Here we share the idea of this paper briefly. We integrate the entire dictionary learning and encoding framework into a single CNN model. This model is compatible with existing deep learning framework and enables end-to-end material/texture recognition. We have achieved state-of-the-art results on several gold-standard benchmarks. As a side product, we obtain 49.8% relative improvement on STL-10 dataset comparing to previous state-of-the-art by joint training with CIFAR-10 dataset. |
Language: 中文
Approaches
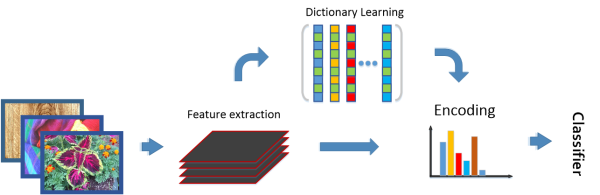
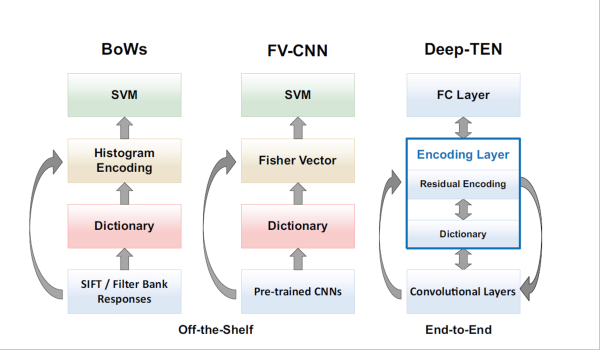
This work is mainly inspired by the classic vision approaches: given an input image, dense features are usually extracted (such as hog, SIFT or filterbank responses). Then a dictionary is usually learned unsupervisely. Given the features and the dictionary, we can build an encoder (BoWs or VQ) which provides a fixed length representation. Finally, a classifier is trained on top. There are two main advantages for classic approaches:
- allowing arbitrary input image sizes,
- the features are generic (domain-independent), and the dictionary and encoding representation usually carries domain information.
Cimpoi et. al. CVPR 2015 introduce a hybrid approach (FV-CNN) which leverages power of the texture encoding representation and deep learning features ( as shown in the middle of above figure). They adopt pre-trained CNN models to extract deep features and built a Fisher Vector encoder and achieved state-of-the-art results. However, there are some limitations:
- this algorithm has some self-contained optimization steps: the dictionary and encoding representations are fixed once built,the feature extraction is not benefiting from the representation and the labeled data,
- pre-trained CNN usually contains domain information.
The ideal solution is shown on the right of above figure, which ports the entire dictionary learning and feature encoding into a single layer to achieve end-to-end recognition. Therefore, we introduce the Encoding Layer and it has the following property:
- generalizing existing residual encoders (VLAD or Fisher Vector),
- make the CNN framework more flexible by allowing arbitrary input image sizes,
- make the convolutional features easier to transfer, since the dictionary learning and encoding representation are likely to carry domain information.
Please refer to our paper for technical details. We also provide an efficient GPU implementation using Torch and PyTorch.