Implementing Synchronized Multi-GPU Batch Normalization¶
In this tutorial, we discuss the implementation detail of Multi-GPU Batch Normalization (BN) (classic implementation: encoding.nn.BatchNorm2d. We will provide the training example in a later version.
How BN works?¶
BN layer was introduced in the paper Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift, which dramatically speed up the training process of the network (enables larger learning rate) and makes the network less sensitive to the weight initialization.
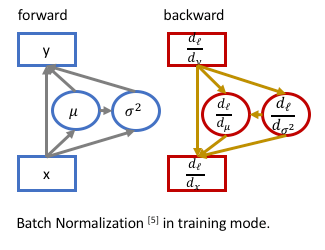
- Forward Pass:
For the input data \(X={x_1, ...x_N}\), the data are normalized to be zero-mean and unit-variance, then scale and shift:
\[y_i = \gamma\cdot\frac{x_i-\mu}{\sigma} + \beta ,\]where \(\mu=\frac{\sum_i^N x_i}{N} , \sigma = \sqrt{\frac{\sum_i^N (x_i-\mu)^2}{N}+\epsilon}\) and \(\gamma, \beta\) are the learnable parameters.
- Backward Pass:
For calculating the gradient \(\frac{d_\ell}{d_{x_i}}\), we need to consider the partial gradient from \(\frac{d_\ell}{d_y}\) and the gradients from \(\frac{d_\ell}{d_\mu}\) and \(\frac{d_\ell}{d_\sigma}\), since the \(\mu \text{ and } \sigma\) are the function of the input \(x_i\). We use partial derivative in the notations:
\[\frac{d_\ell}{d_{x_i}} = \frac{d_\ell}{d_{y_i}}\cdot\frac{\partial_{y_i}}{\partial_{x_i}} + \frac{d_\ell}{d_\mu}\cdot\frac{d_\mu}{d_{x_i}} + \frac{d_\ell}{d_\sigma}\cdot\frac{d_\sigma}{d_{x_i}}\]where \(\frac{\partial_{y_i}}{\partial_{x_i}}=\frac{\gamma}{\sigma}, \frac{d_\ell}{d_\mu}=-\frac{\gamma}{\sigma}\sum_i^N\frac{d_\ell}{d_{y_i}} \text{ and } \frac{d_\sigma}{d_{x_i}}=-\frac{1}{\sigma}(\frac{x_i-\mu}{N})\).
Why Synchronize BN?¶
Standard implementations of BN in public frameworks (such as Caffe, MXNet, Torch, TF, PyTorch) are unsynchronized, which means that the data are normalized within each GPU. Therefore the working batch-size of the BN layer is BatchSize/nGPU (batch-size in each GPU).
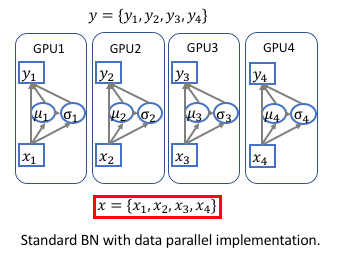
Since the working batch-size is typically large enough for standard vision tasks, such as classification and detection, there is no need to synchronize BN layer during the training. The synchronization will slow down the training.
However, for the Semantic Segmentation task, the state-of-the-art approaches typically adopt dilated convoluton, which is very memory consuming. The working bath-size can be too small for BN layers (2 or 4 in each GPU) when using larger/deeper pre-trained networks, such as
encoding.dilated.ResNetorencoding.dilated.DenseNet.
How to Synchronize?¶
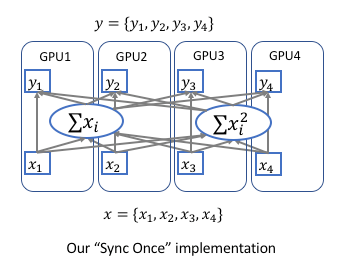
Suppose we have \(K\) number of GPUs, \(sum(x)_k\) and \(sum(x^2)_k\) denotes the sum of elements and sum of element squares in \(k^{th}\) GPU.
- Forward Pass:
We can calculate the sum of elements \(sum(x)=\sum x_i \text{ and sum of squares } sum(x^2)=\sum x_i^2\) in each GPU, then apply
encoding.parallel.allreduceoperation to sum accross GPUs. Then calculate the global mean \(\mu=\frac{sum(x)}{N} \text{ and global variance } \sigma=\sqrt{\frac{sum(x^2)}{N}-\mu^2+\epsilon}\).
- Backward Pass:
\(\frac{d_\ell}{d_{x_i}}=\frac{d_\ell}{d_{y_i}}\frac{\gamma}{\sigma}\) can be calculated locally in each GPU.
Calculate the gradient of \(sum(x)\) and \(sum(x^2)\) individually in each GPU \(\frac{d_\ell}{d_{sum(x)_k}}\) and \(\frac{d_\ell}{d_{sum(x^2)_k}}\).
Then sync the gradient (automatically handled by
encoding.parallel.allreduce) and continue the backward.
Citation¶
Note
This code is provided together with the paper, please cite our work.
Hang Zhang, Kristin Dana, Jianping Shi, Zhongyue Zhang, Xiaogang Wang, Ambrish Tyagi, Amit Agrawal. “Context Encoding for Semantic Segmentation” The IEEE Conference on Computer Vision and Pattern Recognition (CVPR) 2018:
@InProceedings{Zhang_2018_CVPR, author = {Zhang, Hang and Dana, Kristin and Shi, Jianping and Zhang, Zhongyue and Wang, Xiaogang and Tyagi, Ambrish and Agrawal, Amit}, title = {Context Encoding for Semantic Segmentation}, booktitle = {The IEEE Conference on Computer Vision and Pattern Recognition (CVPR)}, month = {June}, year = {2018} }